| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- ML
- rnn
- 딥러닝
- Machine Learning
- 논문리뷰
- Spiking Neural Network
- Generative Model
- Python
- 뉴럴네트워크
- map
- autoencoder
- MLE
- 기계학습
- 인공신경망
- anomalydetection
- 논문 리뷰
- 머신러닝 논문리뷰
- Deep Learning
- ae
- 이상 탐지
- 논문 해석
- 레이텍
- Fast Fourer Transform
- 이상 현상 탐지
- MNIST
- Wavelet Transform
- Snn
- Bagging
- 머신러닝
- Deep Neural Network
- Today
- Total
MATH & ML
Variational Autoencoder(VAE)의 원리와 이해 본문
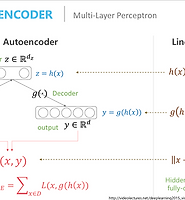
Variational Autoencoder(VAE)는 다시 말하지만 기존의 AE 와 태초부터 탄생 배경이 다른데 다 따지고 결국 전체적인 구조를 보니 AE와 주조가 같아서 autoencoder라는 이름이 붙게 된거라고 볼 수 있다.
VAE의 목적은 어떤 데이터 X에 대해서 그 X에 영향을 주는 어떤 잠재변수(latent variable) Z가 존재한다고 가정을 하고, 그 Z를 찾아내는데에 목적이 있다. 즉 이 Z를 찾아내면 우리는 기존 트레이닝 데이터에 없지만 의미를 가지는 데이터들을 만들어 낼 수 있다는 것이다. 즉 트레이닝 데이터 각 x에 대해서 p(x)를 최대화 시키고 싶은게 목표이다.
$$P(X) = \int_P(X|z)P(z) dz$$
이 VAE에서 generative model관점으로 살펴보면 그냥 바로 주어진 data X에 대하여 그것의 특징 Z를 direct하게 학습하는것이 아니고! 특징들 Z가 주어졌을때 그 때의 데이터 X의 확률을 학습하여 아예 p(X|Z)자체를 학습한다고 생각하면 된다. 이 p(X|Z)라는게 X를 생성하는 모델이기 때문에 generative model이라는 이름이 붙은 것이다. 실제로 이 VAE는 새로운 데이터들을 만들어 낸다고 생각해도 되니까~
그렇다면 우리가 maximize 해야하는 p(x)를 구하는 과정을 보자. 직접 그냥 likelihood estimation으로 최대화하 하면 되는데??라고 생각할 수 있는데 그렇게 하게되면 P(x|z)를 노말분포로 가정하고 계산해보면 예전 포스팅에서 말한것처럼 이를 최대화 하는건 mse error를 최소화 하는것과 같아지는데 여기서는 p(z)가 곱해져서 적분되어서 조금 다를 수도 있는데 결국 보면 비례는 한다. 즉 p(x)의 negative log likelihood가 mse와 비례하게 되는데 실제 아래의 사진에서 (a)가 (c)사진에 더 비슷해야 하는데 그게아니고 (b)와의 MSE가 더 작아지게되는 이상한 점들이 생긴다. 따라서 이 문제를 해결하기 위해서 p(z)를 좀 더 말이 되는 곳에서 뽑을 수 없을까 하는 생각을 갖게되고 이를 variational inference 방법을 이용하여 z를 좋은 것들만 뽑아내서 한 것이 바로 VAE의 아이디어이며 가장 중요한 특징점이다.

(출처 : https://arxiv.org/pdf/1606.05908)
자세한 ELBO, KL 등의 계산과정은 추후에 추가할 예정...
참고
https://www.slideshare.net/ssuser06e0c5/variational-autoencoder-76552518
https://taeoh-kim.github.io/blog/generative-models-part-1-vaegandcgan/
http://www.1-4-5.net/~dmm/ml/vae.pdf
http://jaejunyoo.blogspot.com/2017/04/auto-encoding-variational-bayes-vae-1.html
http://mlg.postech.ac.kr/~seungjin/courses/easyml/handouts/handout04.pdf
'Machine Learning' 카테고리의 다른 글
| Anomaly Detection(이상 탐지, 이상 현상 탐지) (0) | 2018.07.25 |
|---|---|
| Data imputation(결측치 처리) (0) | 2018.07.04 |
| Generative model과 Discriminate model 차이점과 비교 (0) | 2018.06.17 |
| Autoencoder란 개략적 설명과 종류 (0) | 2018.06.15 |
| dimension reduction에 관련된 몇 가지 관점 (0) | 2018.06.07 |